Выбор читателей





Популярные статьи
Исходной для анализа является матрица данных
размерности
 ,
i-я строка которой характеризует i-е
наблюдение (объект) по всем k показателям
,
i-я строка которой характеризует i-е
наблюдение (объект) по всем k показателям .
Исходные данные нормируются, для чего
вычисляются средние значения показателей
.
Исходные данные нормируются, для чего
вычисляются средние значения показателей ,
а также значения стандартных отклонений
,
а также значения стандартных отклонений .
Тогда матрица нормированных значений
.
Тогда матрица нормированных значений

с
элементами

Рассчитывается матрица парных коэффициентов корреляции:

На
главной диагонали матрицы расположены
единичные элементы
 .
.
Модель компонентного анализа строится путем представления исходных нормированных данных в виде линейной комбинации главных компонент:

где
 -
«вес», т.е. факторная нагрузка
-
«вес», т.е. факторная нагрузка -й
главной компоненты на
-й
главной компоненты на -ю
переменную;
-ю
переменную;
 -значение
-значение
 -й
главной компоненты для
-й
главной компоненты для -го
наблюдения (объекта), где
-го
наблюдения (объекта), где .
.
В матричной форме модель имеет вид

здесь
 - матрица главных компонент размерности
- матрица главных компонент размерности ,
,
 -
матрица факторных нагрузок той же
размерности.
-
матрица факторных нагрузок той же
размерности.
Матрица
 описывает
описывает наблюдений в пространстве
наблюдений в пространстве главных компонент. При этом элементы
матрицы
главных компонент. При этом элементы
матрицы нормированы, a главные компоненты не
коррелированы между собой. Из этого
следует, что
нормированы, a главные компоненты не
коррелированы между собой. Из этого
следует, что ,
где
,
где – единичная матрица размерности
– единичная матрица размерности .
.
Элемент
 матрицы
матрицы характеризует тесноту линейной связи
между исходной переменной
характеризует тесноту линейной связи
между исходной переменной и главной компонентой
и главной компонентой ,
следовательно, принимает значения
,
следовательно, принимает значения .
.
Корреляционная
матрица
 может быть выражена через матрицу
факторных нагрузок
может быть выражена через матрицу
факторных нагрузок .
.
По
главной диагонали корреляционной
матрицы располагаются единицы и по
аналогии с ковариационной матрицей они
представляют собой дисперсии используемых
 -признаков,
но в отличие от последней, вследствие
нормировки, эти дисперсии равны 1.
Суммарная дисперсия всей системы
-признаков,
но в отличие от последней, вследствие
нормировки, эти дисперсии равны 1.
Суммарная дисперсия всей системы -признаков
в выборочной совокупности объема
-признаков
в выборочной совокупности объема равна сумме этих единиц, т.е. равна следу
корреляционной матрицы
равна сумме этих единиц, т.е. равна следу
корреляционной матрицы .
.
Корреляционная матриц может быть преобразована в диагональную, то есть матрицу, все значения которой, кроме диагональных, равны нулю:
 ,
,
где
 - диагональная матрица, на главной
диагонали которой находятся собственные
числа
- диагональная матрица, на главной
диагонали которой находятся собственные
числа корреляционной матрицы,
корреляционной матрицы, - матрица, столбцы которой – собственные
вектора корреляционной матрицы
- матрица, столбцы которой – собственные
вектора корреляционной матрицы .
Так как матрица R положительно определена,
т.е. ее главные миноры положительны, то
все собственные значения
.
Так как матрица R положительно определена,
т.е. ее главные миноры положительны, то
все собственные значения для любых
для любых .
.
Собственные
значения
 находятся как корни характеристического
уравнения
находятся как корни характеристического
уравнения

Собственный
вектор
 ,
соответствующий собственному значению
,
соответствующий собственному значению корреляционной матрицы
корреляционной матрицы ,
определяется как отличное от нуля
решение уравнения
,
определяется как отличное от нуля
решение уравнения

Нормированный
собственный вектор
 равен
равен

Превращение
в нуль недиагональных членов означает,
что признаки становятся независимыми
друг от друга ( при
при ).
).
Суммарная
дисперсия всей системы
 переменных в выборочной совокупности
остается прежней. Однако её значения
перераспределяется. Процедура нахождения
значений этих дисперсий представляет
собой нахождение собственных значений
переменных в выборочной совокупности
остается прежней. Однако её значения
перераспределяется. Процедура нахождения
значений этих дисперсий представляет
собой нахождение собственных значений корреляционной матрицы для каждого из
корреляционной матрицы для каждого из -признаков.
Сумма этих собственных значений
-признаков.
Сумма этих собственных значений равна следу корреляционной матрицы,
т.е.
равна следу корреляционной матрицы,
т.е. ,
то есть количеству переменных. Эти
собственные значения и есть величины
дисперсии признаков
,
то есть количеству переменных. Эти
собственные значения и есть величины
дисперсии признаков в условиях, если бы признаки были бы
независимыми друг от друга.
в условиях, если бы признаки были бы
независимыми друг от друга.
В
методе главных компонент сначала по
исходным данным рассчитывается
корреляционная матрица. Затем производят
её ортогональное преобразование и
посредством этого находят факторные
нагрузки
 для всех
для всех переменных и
переменных и факторов (матрицу факторных нагрузок),
собственные значения
факторов (матрицу факторных нагрузок),
собственные значения и определяют веса факторов.
и определяют веса факторов.
Матрицу
факторных нагрузок А можно определить
как
 ,
а
,
а -й
столбец матрицы А - как
-й
столбец матрицы А - как .
.
Вес
факторов
 или
или отражает долю в общей дисперсии, вносимую
данным фактором.
отражает долю в общей дисперсии, вносимую
данным фактором.
Факторные
нагрузки изменяются от –1 до +1 и являются
аналогом коэффициентов корреляции. В
матрице факторных нагрузок необходимо
выделить значимые и незначимые нагрузки
с помощью критерия Стьюдента
 .
.
Сумма
квадратов нагрузок
 -го
фактора во всех
-го
фактора во всех -признаках
равна собственному значению данного
фактора
-признаках
равна собственному значению данного
фактора .
Тогда
.
Тогда -вклад
i-ой переменной в % в формировании j-го
фактора.
-вклад
i-ой переменной в % в формировании j-го
фактора.
Сумма
квадратов всех факторных нагрузок по
строке равна единице, полной дисперсии
одной переменной, а всех факторов по
всем переменным равна суммарной дисперсии
(т.е. следу или порядку корреляционной
матрицы, или сумме её собственных
значений)
 .
.
В
общем виде факторная структура i–го
признака представляется в форме
 ,
в которую включаются лишь значимые
нагрузки. Используя матрицу факторных
нагрузок можно вычислить значения всех
факторов для каждого наблюдения исходной
выборочной совокупности по формуле:
,
в которую включаются лишь значимые
нагрузки. Используя матрицу факторных
нагрузок можно вычислить значения всех
факторов для каждого наблюдения исходной
выборочной совокупности по формуле:
 ,
,
где
 – значение j-ого фактора у t-ого
наблюдения,
– значение j-ого фактора у t-ого
наблюдения, -стандартизированное
значение i–ого признака у t-ого наблюдения
исходной выборки;
-стандартизированное
значение i–ого признака у t-ого наблюдения
исходной выборки; –факторная нагрузка,
–факторная нагрузка, –собственное значение, отвечающее
фактору j. Эти вычисленные значения
–собственное значение, отвечающее
фактору j. Эти вычисленные значения широко используются для графического
представления результатов факторного
анализа.
широко используются для графического
представления результатов факторного
анализа.
По
матрице факторных нагрузок может быть
восстановлена корреляционная матрица:
 .
.
Часть дисперсии переменной, объясняемая главными компонентами, называется общностью
 ,
,
где
 - номер переменной, а
- номер переменной, а -номер главной компоненты. Восстановленные
только по главным компонентам коэффициенты
корреляции будут меньше исходных по
абсолютной величине, а на диагонали
будут не 1, а величины общностей.
-номер главной компоненты. Восстановленные
только по главным компонентам коэффициенты
корреляции будут меньше исходных по
абсолютной величине, а на диагонали
будут не 1, а величины общностей.
Удельный
вклад
 -й
главной компоненты определяется по
формуле
-й
главной компоненты определяется по
формуле
 .
.
Суммарный
вклад учитываемых
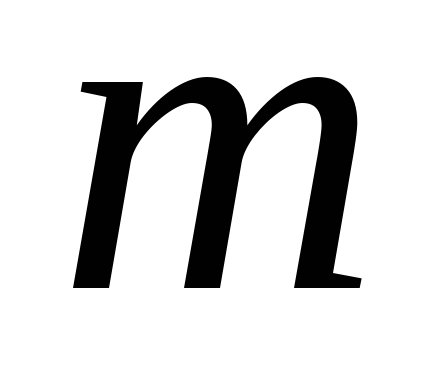 главных компонент определяется из
выражения
главных компонент определяется из
выражения
 .
.
Обычно
для анализа используют
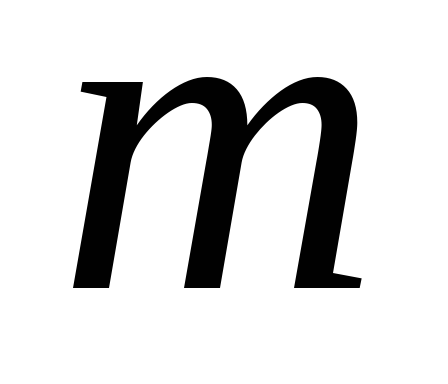 первых главных компонент, вклад которых
в суммарную дисперсию превышает 60-70%.
первых главных компонент, вклад которых
в суммарную дисперсию превышает 60-70%.
Матрица факторных нагрузок А используется для интерпретации главных компонент, при этом обычно рассматриваются те значения, которые превышают 0,5.
Значения главных компонент задаются матрицей

В стремлении предельно точно описать исследуемую область аналитики часто отбирают большое число независимых переменных (p). В этом случае может возникнуть серьезная ошибка: несколько описывающих переменных могут характеризовать одну и ту же сторону зависимой переменной и, как следствие, высоко коррелировать между собой. Мультиколлинеарность независимых переменных серьезно искажает результаты исследования, поэтому от нее следует избавляться.
Метод главных компонент (как упрощенная модель факторного анализа, поскольку при этом методе не используются индивидуальные факторы, описывающие только одну переменную x i) позволяет объединить влияние высоко коррелированных переменных в один фактор, характеризующий зависимую переменную с одной единственной стороны. В результате анализа, осуществленного по методу главных компонент, мы добьемся сжатия информации до необходимых размеров, описания зависимой переменной m (m Для начала необходимо решить, сколько факторов необходимо выделить в данном исследовании. В рамках метода главных компонент первый главный фактор описывает наибольших процент дисперсии независимых переменных, далее – по убывающей. Таким образом, каждая следующая главная компонента, выделенная последовательно, объясняет все меньшую долю изменчивости факторов x i . Задача исследователя состоит в том, чтобы определить, когда изменчивость становится действительно малой и случайной. Другими словами – сколько главных компонент необходимо выбрать для дальнейшего анализа. Существует несколько методов рационального выделения необходимого числа факторов. Наиболее используемый из них – критерий Кайзера. Согласно этому критерию, отбираются только те факторы, собственные значения которых больше 1. Таким образом, фактор, который не объясняет дисперсию, эквивалентную, по крайней мере, дисперсии одной переменной, опускается. Проанализируем Таблицу 19, построенную в SPSS: Таблица 19. Полная объясненная дисперсия Как видно из Таблицы 19, в данном исследовании переменные x i высоко коррелирут между собой (это также выявлено ранее и видно из Таблицы 5 «Парные коэффициенты корреляции»), а следовательно, характеризуют зависимую переменную Y практически с одной стороны: изначально первая главная компонента объясняет 90,7 % дисперсии x i , и только собственное значение, соответствующее первой главной компоненте, больше 1. Конечно, это является недостатком отбора данных, однако в процессе самого отбора этот недостаток не был очевиден. Анализ в пакете SPSS позволяет самостоятельно выбрать число главных компонент. Выберем число 6 – равное количеству независимых переменных. Второй столбец Таблицы 19 показывает суммы квадратов нагрузок вращения, именно по этим результатам и сделаем вывод о числе факторов. Собственные значения, соответствующие первым двум главным компонентам, больше 1 (55,246% и 38,396% соответственно), поэтому, согласно методу Кайзера, выделим 2 наиболее значимые главные компоненты. Второй метод выделения необходимого числа факторов – критерий «каменистой осыпи». Согласно этому методу, собственные значения представляются в виде простого графика, и выбирается такое место на графике, где убывание собственных значений слева направо максимально замедляется: Рисунок 3. Критерий "каменистой осыпи" Как видно на Рисунке 3, убывание собственных значений замедляется уже со второй компоненты, однако постоянная скорость убывания (очень маленькая) начинается лишь с третьей компоненты. Следовательно, для дальнейшего анализа будут отобраны первые две главные компоненты. Это умозаключение согласуется с выводом, полученным при использовании метода Кайзера. Таким образом, окончательно выбираются первые две последовательно полученные главные компоненты. После выделения главных компонент, которые будут использоваться в дальнейшем анализе, необходимо определить корреляцию исходных переменных x i c полученными факторами и, исходя из этого, дать названия компонентам. Для анализа воспользуемся матрицей факторных нагрузок А, элементы которой являются коэффициентами корреляции факторов с исходными независимыми переменными: Таблица 20. Матрица факторных нагрузок В данном случае интерпретация коэффициентов корреляции затруднена, следовательно, довольно сложно дать названия первым двум главным компонентам. Поэтому далее воспользуемся методом ортогонального поворота системы координат Варимакс, целью которого является поворот факторов так, чтобы выбрать простейшую для интерпретации факторную структуру: Таблица 21. Коэффициенты интерпретации Из Таблицы 21 видно, что первая главная компонента больше всего связана с переменными x1, x2, x3; а вторая – с переменными x4, x5, x6. Таким образом, можно сделать вывод, что объем инвестиций в основные средства в регионе (переменная Y)
зависит от двух факторов: - объема собственных и заемных средств, поступивших в предприятия региона за период (первая компонента, z1);
-
а также от интенсивности вложений предприятий региона в финансовые активы и количества иностранного капитала в регионе (вторая компонента, z2).
Рисунок 4. Диаграмма рассеивания Данная диаграмма демонстрирует неутешительные результаты. Еще в самом начале исследования мы старались подобрать данные так, чтобы результирующая переменная Y была распределена нормально, и нам практически это удалось. Законы распределения независимых переменных были достаточно далеки от нормального, однако мы старались максимально приблизить их к нормальному закону (соответствующим образом подобрать данные). Рисунок 4 показывает, что первоначальная гипотеза о близости закона распределения независимых переменных к нормальному закону не подтверждается: форма облака должна напоминать эллипс, в центре объекты должны быть расположены более густо, нежели чем по краям. Стоит заметить, что сделать многомерную выборку, в которой все переменные распределены по нормальному закону – задача, выполнимая с огромным трудом (более того, не всегда имеющая решение). Однако к этой цели нужно стремиться: тогда результаты анализа будут более значимыми и понятными при интерпретации. К сожалению, в нашем случае, когда проделана большая часть работы по анализу собранных данных, менять выборку достаточно затруднительно. Но далее, в последующих работах, стоит более серьезно подходить в выборке независимых переменных и максимально приближать закон их распределения к нормальному. Последним этапом анализа методом главных компонент является построение уравнения регрессии на главные компоненты (в данном случае – на первую и вторую главные компоненты). При помощи SPSS рассчитаем параметры регрессионной модели: Таблица 22. Параметры уравнения регресии на главные компоненты Уравнение регрессии примет вид: y=47 414,184 + 0,916*z1+0,213*z2,
(b0) (b1) (b2)
т. о. b0
=47 414,184
показывает точку пересечения прямой регрессии с осью результирующего показателя; b1= 0,916 –
при увеличении значения фактора z1 на 1 ожидаемое среднее значение суммы объема инвестиций в основные средства увеличится на 0,916; b2= 0,213 –
при увеличении значения фактора z2 на 1 ожидаемое среднее значение суммы объема инвестиций в основные средства увеличится на 0,213. В данном случае значение tкр («альфа»=0,001, «ню»=53) = 3,46 меньше tнабл для всех коэффициентов «бета». Следовательно, все коэффициенты значимы. Таблица 24. Качество регрессионной модели на главные компоненты В Таблице 24 отражены показатели, которые характеризуют качество построенной модели, а именно: R – множественный к-т корреляции – говорит о том, какая доля дисперсии Y объясняется вариацией Z; R^2 – к-т детерминации – показывает долю объяснённой дисперсии отклонений Y от её среднего значения. Стандартная ошибка оценки характеризует ошибку построенной модели. Сравним эти показатели с аналогичными показателями степенной регрессионной модели (ее качество оказалось выше качества линейной модели, поэтому сравниваем именно со степенной): Таблица 25. Качество степенной регрессионной модели Так, множественный к-т корреляции R и к-т детерминации R^2 в степенной модели несколько выше, чем в модели главных компонент. Кроме того, стандартная ошибка модели главных компонент НАМНОГО выше, чем в степенной модели. Поэтому качество степенной регрессионной модели выше, чем регрессионной модели, построенной на главных компонентах. Проведем верификацию регрессионной модели главных компонент, т. е. проанализируем ее значимость. Проверим гипотезу о незначимости модели, рассчитаем F(набл.) = 204,784 (рассчитано в SPSS), F(крит) (0,001; 2; 53)=7,76. F(набл)>F(крит), следовательно, гипотеза о незначимости модели отвергается. Модель значима. Итак, в результате проведения компонентного анализа, было выяснено, что из отобранных независимых переменных x i можно выделить 2 главные компоненты – z1 и z2, причем на z1 в большей степени влияют переменные x1, x2, x3, а на z2 – x4, x5, x6. Уравнение регрессии, построенное на главных компонентах, оказалось значимым, хотя и уступает по качеству степенному уравнению регрессии. Согласно уравнению регрессии на главные компоненты, Y положительно зависит как от Z1, так и от Z2. Однако изначальная мультиколлинеарность переменных xi и то, что они не распределены по нормальному закону распределения, может искажать результаты построенной модели и делать ее менее значимой. Кластерный анализ
Следующим этапом данного исследования является кластерный анализ. Задачей кластерного анализа является разбиение выбранных регионов (n=56) на сравнительно небольшое число групп (кластеров) на основе их естественной близости относительно значений переменных x i . При проведении кластерного анализа мы предполагаем, что геометрическая близость двух или нескольких точек в пространстве означает физическую близость соответствующих объектов, их однородность (в нашем случае - однородность регионов по показателям, влияющим на инвестиции в основные средства). На первой стадии кластерного анализа необходимо определиться с оптимальным числом выделяемых кластеров. Для этого необходимо провести иерархическую кластеризацию – последовательное объединение объектов в кластеры до тех пор, пока не останется два больших кластера, объединяющиеся в один на максимальном расстоянии друг от друга. Результат иерархического анализа (вывод об оптимальном количестве кластеров) зависит от способа расчета расстояния между кластерами. Таким образом, протестируем различные методы и сделаем соответствующие выводы. Метод «ближнего соседа»
Если расстояние между отдельными объектами мы рассчитываем единым способом – как простое евклидово расстояние – расстояние между кластерами вычисляется разными методами. Согласно методу «ближайшего соседа», расстояние между кластерами соответствует минимальному расстоянию между двумя объектами разных кластеров. Анализ в пакете SPSS проходит следующим образом. Сначала рассчитывается матрица расстояний между всеми объектами, а затем, на основе матрицы расстояний, объекты последовательно объединяются в кластеры (для каждого шага матрица составляется заново). Шаги последовательного объединения представлены в таблице: Таблица 26. Шаги агломерации. Метод «ближайшего соседа» Как видно из Таблицы 26, на первом этапе объединились элементы 7 и 8, т. к. расстояние между ними было минимальным – 0,003. Далее расстояние между объединенными объектами увеличивается. По таблице также можно сделать вывод об оптимальном числе кластеров. Для этого нужно посмотреть, после какого шага происходит резкий скачок в величине расстояния, и вычесть номер этой агломерации из числа исследуемых объектов. В нашем случае: (56-53)=3 – оптимальное число кластеров. Рисунок 5. Дендрограмма. Метод "ближайшего соседа" Аналогичный вывод об оптимальном количестве кластеров можно сделать и глядя на дендрограмму (Рис. 5): следует выделить 3 кластера, причем в первый кластер войдут объекты под номерами 1-54 (всего 54 объекта), а во второй и третий кластеры – по одному объекту (под номерами 55 и 56 соответственно). Данный результат говорит о том, что первые 54 региона относительно однородны по показателям, влияющим на инвестиции в основные средства, в то время как объекты под номерами 55 (Республика Дагестан) и 56 (Новосибирская область) значительно выделяются на общем фоне. Стоит заметить, что данные субъекты имеют самые большие объемы инвестиций в основные средства среди всех отобранных регионов. Этот факт еще раз доказывает высокую зависимость результирующей переменной (объема инвестиций) от выбранных независимых переменных. Аналогичные рассуждения проводятся для других методов расчета расстояния между кластерами. Метод «дальнего соседа»
Таблица 27. Шаги агломерации. Метод "дальнего соседа" При методе «дальнего соседа» расстояние между кластерами рассчитывается как максимальное расстояние между двумя объектами в двух разных кластерах. Согласно Таблице 27, оптимальное число кластеров равно (56-53)=3. Рисунок 6. Дендрограмма. Метод "дальнего соседа" Согласно дендрограмме, оптимальным решением также будет выделение 3 кластеров: в первый кластер войдут регионы под номерами 1-50 (50 регионов), во второй – под номерами 51-55 (5 регионов), в третий – последний регион под номером 56. Метод «центра тяжести»
При методе «центра тяжести» за расстояние между кластерами принимается евклидово расстояние между «центрами тяжести» кластеров – средними арифметическими их показателей x i . Рисунок 7. Дендрограмма. Метод "центра тяжести" На Рисунке 7 видно, что оптимальное число кластеров следующее: 1 кластер – 1-47 объекты; 2 кластер – 48-54 объекты (всего 6); 3 кластер – 55 объект; 4 кластер – 56 объект. Принцип «средней связи»
В данном случае расстояние между кластерами равно среднему значению расстояний между всеми возможными парами наблюдений, причем одно наблюдение берется из одного кластера, а второе – соответственно, из другого. Анализ таблицы шагов агломерации показал, что оптимальное количество кластеров равно (56-52)=4. Сравним этот вывод с выводом, полученным при анализе дендрограммы. На Рисунке 8 видно, что в 1 кластер войдут объекты под номерами 1-50, во 2 кластер – объекты 51-54 (4 объекта), в 3 кластер – 55 регион, в 4 кластер – 56 регион. Рисунок 8. Дендрограмма. Метод "средней связи" Главные компоненты
5.1
Методы множественной регрессии и канонической корреляции предполагают разбиение имеющегося набора признаков на две части. Однако, далеко не всегда такое разбиение может быть объективно хорошо обоснованным, в связи с чем возникает необходимость в таких подходах к анализу взаимосвязей показателей, которые предполагали бы рассмотрение вектора признаков как единого целого. Разумеется, при реализации подобных подходов в этой батарее признаков может быть обнаружена определенная неоднородность, когда объективно выявятся несколько групп переменных. Для признаков из одной такой группы взаимные корреляции будут гораздо выше по сравнению с сочетаниями показателей из разных групп. Однако, эта группировка будет опираться на результаты объективного анализа данных, а - не на априорные произвольные соображения исследователя. 5.2
При изучении корреляционных связей внутри некоторого единого набора m признаков X
"= X 1 X 2 X 3 ... X m можно воспользоваться тем же самым способом, который применялся в множественном регрессионном анализе и методе канонических корреляций - получением новых переменных, вариация которых полно отражает существование многомерных корреляций. Целью рассмотрения внутригрупповых связей единого набора признаков является определение и наглядное представление объективно существующих основных направлений соотносительной вариации этих переменных. Поэтому, для этих целей можно ввести некие новые переменные Y i , находимые как линейные комбинации исходного набора признаков X Y 1 = b 1 "X
= b 11 X 1 + b 12 X 2 + b 13 X 3 + ... + b 1m X m Y 2 = b 2 "X
= b 21 X 1 + b 22 X 2 + b 23 X 3 + ... + b 2m X m Y 3 = b 3 "X
= b 31 X 1 + b 32 X 2 + b 33 X 3 + ... + b 3m X m (5.1) ... ... ... ... ... ... ... Y m = b m "X
= b m1 X 1 + b m2 X 2 + b m3 X 3 + ... + b m m X m и обладающие рядом желательных свойств. Пусть для определенности число новых признаков равно числу исходных показателей (m). Одним из таких желательных оптимальных свойств может быть взаимная некор-релированность новых переменных, то есть диагональный вид их ковариационной матрицы S y1 2 0 0 ... 0 0 s y2 2 0 ... 0 S y
= 0 0 s y3 2 ... 0 , (5.2) ... ... ... ... ... 0 0 0 … s ym 2 где s yi 2 - дисперсия i-го нового признака Y i . Некоррелированность новых переменных кроме своего очевидного удобства имеет важное свойство - каждый новый признак Y i будет учитывать только свою независимую часть информации об изменчивости и коррелированности исходных показателей X. Вторым необходимым свойством новых признаков является упорядоченный учет вариации исходных показателей. Так, пусть первая новая переменная Y 1 будет учитывать максимальную долю суммарной вариации признаков X. Это, как мы позже увидим, равносильно требованию того, чтобы Y 1 имела бы максимально возможную дисперсию s y1 2 . С учетом равенства (1.17) это условие может быть записано в виде s y1 2 = b 1 "Sb 1
= max , (5.3) где S
- ковариационная матрица исходных признаков X, b 1
- вектор, включающий коэффициенты b 11 , b 12 , b 13 , ..., b 1m при помощи которых, по значениям X 1 , X 2 , X 3 , ..., X m можно получить значение Y 1 . Пусть вторая новая переменная Y 2 описывает максимальную часть того компонента суммарной вариации, который остался после учета наибольшей его доли в изменчивости первого нового признака Y 1 . Для достижения этого необходимо выполнение условия s y2 2 = b 2 "Sb 2
= max , (5.4) при нулевой связи Y 1 с Y 2 , (т.е. r y1y2 = 0) и при s y1 2 > s y2 2 . Аналогичным образом, третий новый признак Y 3 должен описывать третью по степени важности часть вариации исходных признаков, для чего его дисперсия должна быть также максимальной s y3 2 = b 3 "Sb 3
= max , (5.5) при условиях, что Y 3 нескоррелирован с первыми двумя новыми признаками Y 1 и Y 2 (т.е. r y1y3 = 0, r y2y3 = 0) и s y1 2 > s y2 > s y3 2 . Таким образом, для дисперсий всех новых переменных характерна упорядоченность по величине s y1 2 > s y2 2 > s y3 2 > ... > s y m 2 . (5.6) 5.3
Векторы из формулы (5.1) b
1 , b
2 , b
3 , ..., b
m , при помощи которых должен осу-ществляться переход к новым переменным Y i , могут быть записаны в виде матрицы B
= b
1 b
2 b
3 ... b
m . (5.7) Переход от набора исходных признаков X
к набору новых переменных Y
может быть представлен в виде матричной формулы Y
= B" X
, (5.8) а получение ковариационной матрицы новых признаков и достижение условия (5.2) некоррелированности новых переменных в соответствии с формулой (1.19) может быть представлено в виде B"SB
= S y
, (5.9) где ковариационная матрица новых переменных S y
в силу их некоррелированности имеет диагональную форму. Из теории матриц (раздел А.25
Приложения А) известно, что, полу-чив для некоторой симметрической матрицы A
собственные векторы u i
и числа l i и обра- зовав из них матрицы U
и L
, можно в соответствии с формулой (А.31) получить результат U"AU
= L
, где L
- диагональная матрица, включающая собственные числа симметрической матрицы A
. Нетрудно видеть, что последнее равенство полностью совпадает с формулой (5.9). Поэтому, можно сделать следующий вывод. Желательные свойства новых переменных Y
можно обеспечить, если векторы b
1 , b
2 , b
3 , ..., b
m , при помощи которых должен осуществляться переход к этим переменным, будут собственными векторами ковариационной матрицы исходных признаков S
. Тогда дисперсии новых признаков s yi 2 окажутся собственными числами s y1 2 = l 1 , s y2 2 = l 2 , s y3 2 = l 3 , ... , s ym 2 = l m (5.10) Новые переменные, переход к которым по формулам (5.1) и (5.8) осуществляется при помощи собственных векторов ковариационной матрицы исходных признаков, называются главными компонентами. В связи с тем, что число собственных векторов ковариационной матрицы в общем случае равно m - числу исходных признаков для этой матрицы, количество главных компонент также равно m. В соответствии с теорией матриц для нахождения собственных чисел и векторов ковариационной матрицы следует решить уравнение (S
- l i I
)b
i = 0
. (5.11) Это уравнение имеет решение, если выполняется условие равенства нулю определителя ½S
- l i I
½ = 0 . (5.12) Это условие по существу также оказывается уравнением, корнями которого являются все собственные числа l 1 , l 2 , l 3 , ..., l m ковариационной матрицы одновременно совпадающие с дисперсиями главных компонент. После получения этих чисел, для каждого i-го из них по уравнению (5.11) можно получить соответствующий собственный вектор b
i . На практике для вычисления собственных чисел и векторов используются специальные итерационные процедуры (Приложение В). Все собственные векторы можно записать в виде матрицы B
, которая будет ортонормированной матрицей, так что (раздел А.24
Приложения А) для нее выполняется B"B
= BB"
= I
. (5.13) Последнее означает, что для любой пары собственных векторов справедливо b i "b j
= 0, а для любого такого вектора соблюдается равенство b i "b i
= 1. 5.4
Проиллюстрируем получение главных компонент для простейшего случая двух исходных признаков X 1 и X 2 . Ковариационная матрица для этого набора равна где s 1 и s 2 - средние квадратические отклонения признаков X 1 и X 2 , а r - коэффициент корреляции между ними. Тогда условие (5.12) можно записать в виде S 1 2 - l i rs 1 s 2 rs 1 s 2 s 2 2 - l i Рисунок 5.1
.Геометрический смысл главных компонент Раскрывая определитель, можно получить уравнение l 2 - l(s 1 2 + s 2 2) + s 1 2 s 2 2 (1 - r 2) = 0 , решая которое, можно получить два корня l 1 и l 2 . Уравнение (5.11) может быть также записано в виде s 1 2 - l i r s 1 s 2 b i1 = 0 r s 1 s 2 s 2 2 - l i b i2 0 Подставляя в это уравнение l 1 , получим линейную систему (s 1 2 - l 1) b 11 + rs 1 s 2 b 12 = 0 rs 1 s 2 b 11 + (s 2 2 - l 1)b 12 = 0 , решением которой являются элементы первого собственного вектора b 11 и b 12 . После аналогичной подстановки второго корня l 2 найдем элементы второго собственного вектора b 21 и b 22 . 5.5
Выясним геометрический смысл главных компонент. Наглядно это можно сделать лишь для простейшего случая двух признаков X 1 и X 2 . Пусть для них характерно двумерное нормальное распределение с положительным значением коэффициента корреляции. Если все индивидуальные наблюдения нанести на плоскость, образованную осями признаков, то соответствующие им точки расположатся внутри некоторого корреляционного эллипса (рис.5.1). Новые признаки Y 1 и Y 2 также могут быть изображены на этой же плоскости в виде новых осей. По смыслу метода для первой главной компоненты Y 1 , учитывающей максимально возможную суммарную дисперсию признаков X 1 и X 2 , должен достигаться максимум ее дисперсии. Это означает, что для Y 1 следует найти та- кую ось, чтобы ширина распределения ее значений была бы наибольшей. Очевидно, что это будет достигаться, если эта ось совпадет по направлению с наибольшей осью корреляционного эллипса. Действительно, если мы спроецируем все соответствующие индивидуальным наблюдениям точки на эту координату, то получим нормальное распределение с максимально возможным размахом и наибольшей дисперсией. Это будет распределение индивидуальных значений первой главной компоненты Y 1 . Ось, соответствующая второй главной компоненте Y 2 , должна быть проведена перпендикулярно к первой оси, так как это следует из условия некоррелированности главных компонент. Действительно, в этом случае мы получим новую систему координат с осями Y 1 и Y 2 , совпадающими по направлению с осями корреляционного эллипса. Можно видеть, что корреляционный эллипс при его рассмотрении в новой системе координат демонстрирует некоррелированность индивидуальных значений Y 1 и Y 2 , тогда как для величин исходных признаков X 1 и X 2 корреляция наблюдалась. Переход от осей, связанных с исходными признаками X 1 и X 2 , к новой системе координат, ориентированной на главные компоненты Y 1 и Y 2 , равносилен повороту старых осей на некоторый угол j. Его величина может быть найдена по формуле Tg 2j = . (5.14) Переход от значений признаков X 1 и X 2 к главным компонентам может быть осуществлен в соответствии с результатами аналитической геометрии в виде Y 1 = X 1 cos j + X 2 sin j Y 2 = - X 1 sin j + X 2 cos j . Этот же результат можно записать в матричном виде Y 1 = cos j sin j X 1 и Y 2 = -sin j cos j X 1 , который точно соответствует преобразованию Y 1 = b 1 "X
и Y 2 = b 2 "X
. Иными словами, = B"
. (5.15) Таким образом, матрица собственных векторов может также трактоваться как включающая тригонометрические функции угла поворота, который следует осуществить для перехода от системы координат, связанной с исходными признаками, к новым осям, опирающимся на главные компоненты. Если мы имеем m исходных признаков X 1 , X 2 , X 3 , ..., X m , то наблюдения, состав-ляющие рассматриваемую выборку, расположатся внутри некоторого m-мерного корреляционного эллипсоида. Тогда ось первой главной компоненты совпадет по направлению с наибольшей осью этого эллипсоида, ось второй главной компоненты - со второй осью этого эллипсоида и т.д. Переход от первоначальной системы координат, связанной с осями признаков X 1 , X 2 , X 3 , ..., X m к новым осям главных компонент окажется равносильным осуществлению нескольких поворотов старых осей на углы j 1 , j 2 , j 3 , ..., а матрица перехода B
от набора X
к системе главных компонент Y
, состоящая из собственных век- торов ковариационной матрицы, включает в себя тригонометрические функции углов новых координатных осей со старыми осями исходных признаков. 5.6
В соответствии со свойствами собственных чисел и векторов следы ковариа-ционных матриц исходных признаков и главных компонент - равны. Иными словами tr S
= tr S
y = tr L
(5.16) s 11 + s 22 + ... + s mm = l 1 + l 2 + ... + l m , т.е. сумма собственных чисел ковариационной матрицы равна сумме дисперсий всех исходных признаков. Поэтому, можно говорить о некоторой суммарной величине дисперсии исходных признаков равной tr S
, и учитываемой системой собственных чисел. То обстоятельство, что первая главная компонента имеет максимальную дисперсию, равную l 1 , автоматически означает, что она описывает и максимальную долю суммарной вариации исходных признаков tr S
. Аналогично, вторая главная компонента имеет вторую по величине дисперсию l 2 , что соответствует второй по величине учитываемой доле суммарной вариации исходных признаков и т.д. Для каждой главной компоненты можно определить долю суммарной величины изменчивости исходных признаков, которую она описывает 5.7
Очевидно, представление о суммарной вариации набора исходных признаков X 1 , X 2 , X 3 , ..., X m , измеряемой величиной tr S
, имеет смысл только в том случае, когда все эти признаки измерены в одинаковых единицах. В противном случае придется складывать дисперсии, разных признаков, одни из которых будут выражены в квадратах миллиметров, другие - в квадратах килограммов, третьи – в квадратах радиан или градусов и т.д. Этого затруднения легко избежать, если от именованных значений признаков X ij перейти к их нормированным величинам z ij = (X ij - M i)./ S i где M i и S i - средняя арифметическая величина и среднее квадратическое отклонение i-го признака. Нормированные признаки z имеют нулевые средние, единичные дисперсии и не связаны с какими-либо единицами измерения. Ковариационная матрица исходных признаков S
превратится в корреляционную матрицу R
. Все сказанное о главных компонентах, находимых для ковариационной матрицы, остается справедливым и для матрицы R
. Здесь точно также можно, опираясь на собственные векторы корреляционной матрицы b
1 , b
2 , b
3 , ..., b
m , перейти от исходных признаков z i к главным компонентам y 1 , y 2 , y 3 , ..., y m y 1 = b 1 "z
y 2 = b 2 "z
y 3 = b 3 "z
y m = b m "z
. Это преобразование можно также записать в компактном виде y
= B"z
, Рисунок 5.2
.
Геометрический смысл главных компонент для двух нормированных признаков z 1 и z 2 где y
- вектор значений главных компонент, B
- матрица, включающая собственные векторы, z
- вектор исходных нормированных признаков. Справедливым оказывается и равенство B"RB
= ... ... … , (5.18) где l 1 , l 2 , l 3 , ..., l m - собственные числа корреляционной матрицы. Результаты, получающиеся при анализе корреляционной матрицы, отличаются от аналогичных результатов для матрицы ковариационной. Во-первых, теперь можно рассматривать признаки, измеренные в разных единицах. Во-вторых, собственные векторы и числа, найденные для матриц R
и S
, также различны. В-третьих, главные компоненты, определенные по корреляционной матрице и опирающиеся на нормированные значения признаков z, оказываются центрироваными - т.е. имеющими нулевые средние величины. К сожалению, определив собственные векторы и числа для корреляционной матрицы, перейти от них к аналогичным векторами и числам ковариационной матрицы - невозможно. На практике обычно используются главные компоненты, опирающиеся на корреляционную матрицу, как более универсальные. 5.8
Рассмотрим геометрический смысл главных компонент, определенных по корреляционной матрице. Наглядным здесь оказывается случай двух признаков z 1 и z 2 . Система координат, связанная с этими нормированными признаками, имеет нулевую точку, размещенную в центре графика (рис.5.2). Центральная точка корреляционного эллипса, включающего все индивидуальные наблюдения, совпадет с центром системы координат. Очевидно, что ось первой главной компоненты, имеющая максимальную вариацию, совпадет с наибольшей осью корреляционного эллипса, а координата второй главной компоненты будет сориентирована по второй оси этого эллипса. Переход от системы координат, связанной с исходными признаками z 1 и z 2 к новым осям главных компонент равносилен повороту первых осей на некоторый угол j. Дисперсии нормированных признаков равны 1 и по формуле (5.14) можно найти величину угла поворота j равную 45 o . Тогда матрица собственных векторов, которую можно определить через тригонометрические функции этого угла по формуле (5.15), будет равна Cos j sin j 1 1 1 B
" = = . Sin j cos j (2) 1/2 -1 1 Значения собственных чисел для двумерного случая также несложно найти. Условие (5.12) окажется вида что соответствует уравнению l 2 - 2l + 1 - r 2 = 0 , которое имеет два корня l 1 = 1 + r (5.19) Таким образом, главные компоненты корреляционной матрицы для двух нормированных признаков могут быть найдены по очень простым формулам Y 1 = (z 1 + z 2) (5.20) Y 2 = (z 1 - z 2) Их средние арифметические величины равны нулю, а средние квадратические отклонения имеют значения s y1 = (l 1) 1/2 = (1 + r) 1/2 s y2 = (l 2) 1/2 = (1 - r) 1/2 5.9
В соответствии со свойствами собственных чисел и векторов следы корреляционной матрицы исходных признаков и матрицы собственных чисел - равны. Суммарная вариация m нормированных признаков равна m. Иными словами tr R
= m = tr L
(5.21) l 1 + l 2 + l 3 + ... + l m = m . Тогда доля суммарной вариации исходных признаков, описываемая i-ой главной компонентой равна Можно также ввести понятие P cn - доли суммарной вариации исходных признаков, описываемой первыми n главными компонентами, n l 1 + l 2 + ... + l n P cn = S P i = . (5.23) То обстоятельство, что для собственных чисел наблюдается упорядоченность вида l 1 > l 2 > > l 3 > ... > l m , означает, что аналогичные соотношения будут свойственны и долям, описываемой главными компонентами вариации P 1 > P 2 > P 3 > ... > P m . (5.24) Свойство (5.24) влечет за собой специфический вид зависимости накопленной доли P сn от n (рис.5.3). В данном случае первые три главные компоненты описывают основную часть изменчивости признаков. Это означает, что часто немногие первые главные компоненты могут совместно учитывать до 80 - 90% суммарной вариации признаков, тогда как каждая последующая главная компонента будет увеличивать эту долю весьма незначительно. Тогда для дальнейшего рассмотрения и интерпретации можно использовать только эти немногие первые главные компоненты с уверенностью, что именно они описывают наиболее важные закономерности внутригрупповой изменчивости и коррелированности Рисунок 5.3.
Зависимость доли суммарной вариации признаков P cn , описываемой n первыми главными компонентами, от величины n. Число признаков m = 9 Рисунок 5.4. К определению конструкции критерия отсеивания главных компонент
признаков. Благодаря этому, число информативных новых переменных, с которыми следует работать, может быть уменьшено в 2 - 3 раза. Таким образом, главные компоненты имеют еще одно важное и полезное свойство - они значительно упрощают описание вариации исходных признаков и делают его более компактным. Такое уменьшение числа переменных всегда желательно, но оно связано с некоторыми искажениями взаимного расположения точек, соответствующих отдельным наблюдениям, в пространстве немногих первых главных компонент по сравнению с m-мерным пространством исходных признаков. Эти искажения возникают из-за попытки втиснуть пространство признаков в пространство первых главных компонент. Однако, в математической статистике доказывается, что из всех методов, позволяющих значительно уменьшить число переменных, переход к главным компонентам приводит к наименьшим искажениям структуры наблюдений связанных с этим уменьшением. 5.10
Важным вопросом анализа главных компонент является проблема определения их количества для дальнейшего рассмотрения. Очевидно, что увеличение числа главных компонент повышает накопленную долю учитываемой изменчивости P cn и приближает ее к 1. Одновременно, компактность получаемого описания уменьшается. Выбор того количества главных компонент, которое одновременно обеспечивает и полноту и компактность описания может базироваться на разных критериях, применяемых на практике. Перечислим наиболее распространенные из них. Первый критерий основан на том соображении, что количество учитываемых главных компонент должно обеспечивать достаточную информативную полноту описания. Иными словами, рассматриваемые главные компоненты должны описывать большую часть суммарной изменчивости исходных признаков: до 75 - 90%. Выбор конкретного уровня накопленной доли P cn остается субъективным и зависящим как от мнения исследователя, так и от решаемой задачи. Другой аналогичный критерий (критерий Кайзера) позволяет включать в рассмотрение главные компоненты с собственными числами большими 1. Он основан на том соображении, что 1 - это дисперсия одного нормированного исходного признака. Поэто- му, включение в дальнейшее рассмотрение всех главных компонент с собственными числами большими 1 означает что мы рассматриваем только те новые переменные, которые имеют дисперсии не меньше чем у одного исходного признака. Критерий Кайзера весьма распространен и его использование заложено во многие пакеты программ статистической обработки данных, когда требуется задать минимальную величину учитываемого собственного числа, и по умолчанию часто принимается значение равное 1. Несколько лучше теоретически обоснован критерий отсеивания Кеттела. Его применение основано на рассмотрении графика, на котором нанесены значения всех собственных чисел в порядке их убывания (рис.5.4). Критерий Кеттела основан на том эффекте, что нанесенная на график последовательность величин полученных собственных чисел обычно дает вогнутую линию. Несколько первых собственных чисел обнаруживают непрямолинейное уменьшение своего уровня. Однако, начиная с некоторого собственного числа, уменьшение этого уровня становится примерно прямолинейным и довольно пологим. Включение главных компонент в рассмотрение завершается той из них, собственное число которой начинает прямолинейный пологий участок графика. Так, на рисунке 5.4 в соответствие с критерием Кеттела в рассмотрение следует включить только первые три главные компоненты, потому что третье собственное число находится в самом начале прямолинейного пологого участка графика. Критерий Кеттела основан на следующем. Если рассматривать данные по m признакам, искусственно полученные из таблицы нормально распределенных случайных чисел, то для них корреляции между признаками будут носить совершенно случайный характер и будут близкими к 0. При нахождении здесь главных компонент можно будет обнаружить постепенное уменьшение величины их собственных чисел, имеющее прямолинейной характер. Иными словами, прямолинейное уменьшение собственных чисел может свидетельствовать об отсутствии в соответствующей им информации о коррелированности признаков неслучайных связей. 5.11
При интерпретации главных компонент чаще всего используются собственные векторы, представленные в виде так называемых нагрузок - коэффициентов корреляции исходных признаков с главными компонентами. Собственные векторы b i
, удовлетворяющие равенству (5.18), получаются в нормированном виде, так что b i "b i
= 1. Это означает, что сумма квадратов элементов каждого собственного вектора равна 1. Собственные векторы, элементы которых являются нагрузками, могут быть легко найдены по формуле a i
= (l i) 1/2 b i
. (5.25) Иными словами, домножением нормированной формы собственного вектора на корень квадратный его собственного числа, можно получить набор нагрузок исходных признаков на соответствующую главную компоненту. Для векторов нагрузок справедливым оказывается равенство a i "a i
= l i , означающее, что сумма квадратов нагрузок на i-ю главную компоненту равна i-му собственному числу. Компьютерные программы обычно выводят собственные векторы именно в виде нагрузок. При необходимости получения этих векторов в нормированном виде b i
это можно сделать по простой формуле b i
= a i
/ (l i) 1/2 . 5.12
Математические свойства собственных чисел и векторов таковы, что в соответствии с разделом А.25
Приложения А исходная корреляционная матрица R
может быть представлена в виде R
= BLB"
, что также можно записать как R
= l 1 b 1 b 1 "
+ l 2 b 2 b 2 "
+ l 3 b 3 b 3 "
+ ... + l m b
m b
m "
. (5.26) Следует заметить, что любой из членов l i b i b i "
, соответствующий i-й главной компоненте, является квадратной матрицей L i b i1 2 l i b i1 b i2 l i b i1 b i3 … l i b i1 b im l i b i b i "
= l i b i1 b i2 l i b i2 2 l i b i2 b i3 ... l i b i2 b im . (5.27) ... ... ... ... ... l i b i1 b im l i b i2 b im l i b i3 b im ... l i b im 2 Здесь b ij - элемент i-го собственного вектора у j-го исходного признака. Любой диагональный член такой матрицы l i b ij 2 есть некоторая доля вариации j-го признака, описываемая i-й главной компонентой. Тогда дисперсия любого j-го признака может быть представлена в виде 1 = l 1 b 1j 2 + l 2 b 2j 2 + l 3 b 3j 2 + ... + l m b mj 2 , (5.28) означающем ее разложение по вкладам, зависящим от всех главных компонент. Аналогично, любой внедиагональный член l i b ij b ik матрицы (5.27) является некоторой частью коэффициента корреляции r jk j-го и k-го признаков, учитываемой i-й главной компонентой. Тогда можно выписать разложение этого коэффициента в виде суммы r jk = l 1 b 1j b 1k + l 2 b 2j b 2k + ... + l m b mj b mk , (5.29) вкладов в него всех m главных компонент. Таким образом, из формул (5.28) и (5.29) можно наглядно видеть, что каждая главная компонента описывает определенную часть дисперсии каждого исходного признака и коэффициента корреляции каждого их сочетания. С учетом, того, что элементы нормированной формы собственных векторов b ij связаны с нагрузками a ij простым соотношением (5.25), разложение (5.26) может быть выписано и через собственные векторы нагрузок R
= AA"
, что также можно представить как R
= a 1 a 1
" + a 2 a 2
" + a 3 a 3
" + ... + a m a m
" , (5.30) т.е. как сумму вкладов каждой из m главных компонент. Каждый из этих вкладов a i a i "
можно записать в виде матрицы A i1 2 a i1 a i2 a i1 a i3 ... a i1 a im a i1 a i2 a i2 2 a i2 a i3 ... a i2 a im a i a i "
= a i1 a i3 a i2 a i3 a i3 2 ... a i3 a im , (5.31) ... ... ... ... ... a i1 a im a i2 a im a i3 a im ... a im 2 на диагоналях которой размещены a ij 2 - вклады в дисперсию j-го исходного признака, а внедиагональные элементы a ij a ik - есть аналогичные вклады в коэффициент корреляции r jk j-го и k-го признаков. Компонентный анализ относится к многомерным методам снижения размерности. Он содержит один метод - метод главных компонент. Главные компоненты представляют собой ортогональную систему координат, в которой дисперсии компонент характеризуют их статистические свойства. Учитывая, что объекты исследования в экономике характеризуются большим, но конечным количеством признаков, влияние которых подвергается воздействию большого количества случайных причин. Первой главной компонентой Z1 исследуемой системы признаков Х1, Х2, Х3 , Х4 ,…, Хn называется такая центрировано - нормированная линейная комбинация этих признаков, которая среди прочих центрировано - нормированных линейных комбинаций этих признаков, имеет дисперсию наиболее изменчивую. В качестве второй главной компоненты Z2 мы будем брать такую центрировано - нормированную комбинацию этих признаков, которая: не коррелированна с первой главной компонентой, не коррелированны с первой главной компонентой, эта комбинация имеет наибольшую дисперсию. K-ой главной компонентой Zk (k=1…m) мы будем называть такую центрировано - нормированную комбинацию признаков, которая: не коррелированна с к-1 предыдущими главными компонентами, среди всех возможных комбинаций исходных признаков, которые не не коррелированны с к-1 предыдущими главными компонентами, эта комбинация имеет наибольшую дисперсию. Введём ортогональную матрицу U и перейдём от переменных Х к переменным Z, причём Вектор выбирается т. о., чтобы дисперсия была максимальной. После получения выбирается т. о., чтобы дисперсия была максимальной при условии, что не коррелированно с и т. д. Так как признаки измерены в несопоставимых величинах, то удобнее будет перейти к центрированно-нормированным величинам. Матрицу исходных центрированно-нормированных значений признаков найдем из соотношения: где - несмещенная, состоятельная и эффективная оценка математического ожидания, Несмещенная, состоятельная и эффективная оценка дисперсии. Матрица наблюденных значений исходных признаков приведена в Приложении. Центрирование и нормирование произведено с помощью программы"Stadia". Так как признаки центрированы и нормированы, то оценку корреляционной матрицы можно произвести по формуле: Перед тем как проводить компонентный анализ, проведем анализ независимости исходных признаков. Проверка значимости матрицы парных корреляций с помощью критерия Уилкса. Выдвигаем гипотезу: Н0: незначима Н1: значима 125,7; (0,05;3,3) = 7,8 т.к > , то гипотеза Н0 отвергается и матрица является значимой, следовательно, имеет смысл проводить компонентный анализ. Проверим гипотезу о диагональности ковариационной матрицы Выдвигаем гипотезу: Строим статистику, распределена по закону с степенями свободы. 123,21, (0,05;10) =18,307 т.к >, то гипотеза Н0 отвергается и имеет смысл проводить компонентный анализ. Для построения матрицы факторных нагрузок необходимо найти собственные числа матрицы, решив уравнение. Используем для этой операции функцию eigenvals системы MathCAD, которая возвращает собственные числа матрицы: Т.к. исходные данные представляют собой выборку из генеральной совокупности, то мы получили не собственные числа и собственные вектора матрицы, а их оценки. Нас будет интересовать на сколько “хорошо” со статистической точки зрения выборочные характеристики описывают соответствующие параметры для генеральной совокупности. Доверительный интервал для i-го собственного числа ищется по формуле: Доверительные интервалы для собственных чисел в итоге принимают вид: Оценка значения нескольких собственных чисел попадает в доверительный интервал других собственных чисел. Необходимо проверить гипотезу о кратности собственных чисел. Проверка кратности производится с помощью статистики где r-количество кратных корней. Данная статистика в случае справедливости распределена по закону с числом степеней свободы. Выдвинем гипотезы: Так как, то гипотеза отвергается, то есть собственные числа и не кратны. Так как, то гипотеза отвергается, то есть собственные числа и не кратны. Необходимо выделить главные компоненты на уровне информативности 0,85. Мера информативности показывает какую часть или какую долю дисперсии исходных признаков составляют k-первых главных компонент. Мерой информативности будем называть величину: На заданном уровне информативности выделено три главных компоненты. Запишем матрицу = Для получения нормализованного вектора перехода от исходных признаков к главным компонентам необходимо решить систему уравнений: , где - соответствующее собственное число. После получения решения системы необходимо затем нормировать полученный вектор. Для решения данной задачи воспользуемся функцией eigenvec системы MathCAD, которая возвращает нормированный вектор для соответствующего собственного числа. В нашем случае первых четырех главных компонент достаточно для достижения заданного уровня информативности, поэтому матрица U (матрица перехода от исходного базиса к базису из собственных векторов) Строим матрицу U, столбцами которой являются собственные вектора: Матрица весовых коэффициентов: Коэффициенты матрицы А являются коэффициентами корреляции между центрировано - нормированными исходными признаками и ненормированными главными компонентами, и показывают наличие, силу и направление линейной связи между соответствующими исходными признаками и соответствующими главными компонентами. В этой статье я бы хотел рассказать о том, как именно работает метод анализа главных компонент (PCA – principal component analysis) с точки зрения интуиции, стоящей за ее математическим аппаратом. Максимально просто, но подробно. В анализе данных, как и в любом другом анализе, порой бывает нелишним создать упрощенную модель, максимально точно описывающую реальное положение дел. Часто бывает так, что признаки довольно сильно зависят друг от друга и их одновременное наличие избыточно. К примеру, расход топлива у нас меряется в литрах на 100 км, а в США в милях на галлон. На первый взгляд, величиные разные, но на самом деле они строго зависят друг от друга. В миле 1600км, а в галлоне 3.8л. Один признак строго зависит от другого, зная один, знаем и другой. Но гораздо чаще бывает так, что признаки зависят друг от друга не так строго и (что важно!) не так явно. Объем двигателя в целом положительно влияет на разгон до 100 км/ч, но это верно не всегда. А еще может оказаться, что с учетом не видимых на первый взгляд факторов (типа улучшения качества топлива, использования более легких материалов и прочих современных достижений), год автомобиля не сильно, но тоже влияет на его разгон. Зная зависимости и их силу, мы можем выразить несколько признаков через один, слить воедино, так сказать, и работать уже с более простой моделью. Конечно, избежать потерь информации, скорее всего не удастся, но минимизировать ее нам поможет как раз метод PCA. Выражаясь более строго, данный метод аппроксимирует n-размерное облако наблюдений до эллипсоида (тоже n-мерного), полуоси которого и будут являться будущими главными компонентами. И при проекции на такие оси (снижении размерности) сохраняется наибольшее количество информации. Здесь для простоты примера я не буду брать реальные обучающие датасеты на десятки признаков и сотни наблюдений, а сделаю свой, максимально простой игрушечный пример. 2 признака и 10 наблюдений будет вполне достаточно для описания того, что, а главное – зачем, происходит в недрах алгоритма. Сгенерируем выборку: X = np.arange(1,11)
y = 2 * x + np.random.randn(10)*2
X = np.vstack((x,y))
print X
OUT:
[[ 1. 2. 3. 4. 5.
6. 7. 8. 9. 10. ]
[ 2.73446908 4.35122722 7.21132988 11.24872601 9.58103444
12.09865079 13.78706794 13.85301221 15.29003911 18.0998018 ]]
В данной выборке у нас имеются два признака, сильно коррелирующие друг с другом. С помощью алгоритма PCA мы сможем легко найти признак-комбинацию и, ценой части информации, выразить оба этих признака одним новым. Итак, давайте разбираться! Для начала немного статистики. Вспомним, что для описания случайной величины используются моменты. Нужные нам – мат. ожидание и дисперсия. Можно сказать, что мат. ожидание – это «центр тяжести» величины, а дисперсия – это ее «размеры». Грубо говоря, мат. ожидание задает положение случайной величины, а дисперсия – ее размер. Сам процесс проецирования на вектор никак не влияет на значения средних, так как для минимизации потерь информации наш вектор должен проходить через центр нашей выборки. Поэтому нет ничего страшного, если мы отцентрируем нашу выборку – линейно сдвинем ее так, чтобы средние значения признаков были равны 0. Это очень сильно упростит наши дальнейшие вычисления (хотя, стоит отметить, что можно обойтись и без центрирования). Xcentered = (X - x.mean(), X - y.mean())
m = (x.mean(), y.mean())
print Xcentered
print "Mean vector: ", m
OUT:
(array([-4.5, -3.5, -2.5, -1.5, -0.5, 0.5, 1.5, 2.5, 3.5, 4.5]),
array([-8.44644233, -8.32845585, -4.93314426, -2.56723136, 1.01013247,
0.58413394, 1.86599939, 7.00558491, 4.21440647, 9.59501658]))
Mean vector: (5.5, 10.314393916)
Дисперсия же сильно зависит от порядков значений случайной величины, т.е. чувствительна к масштабированию. Поэтому если единицы измерения признаков сильно различаются своими порядками, крайне рекомендуется стандартизировать их. В нашем случае значения не сильно разнятся в порядках, так что для простоты примера мы не будем выполнять эту операцию. В случае с многомерной случайной величиной (случайным вектором) положение центра все так же будет являться мат. ожиданиями ее проекций на оси. А вот для описания ее формы уже недостаточно толькое ее дисперсий по осям. Посмотрите на эти графики, у всех трех случайных величин одинаковые мат.ожидания и дисперсии, а их проекции на оси в целом окажутся одинаковы! Для описания формы случайного вектора необходима ковариационная матрица.
Это матрица, у которой (i,j)
-элемент является корреляцией признаков (X i , X j). Вспомним формулу ковариации: В нашем случае она упрощается, так как E(X i) = E(X j) = 0: Заметим, что когда X i = X j: и это справедливо для любых случайных величин. Таким образом, в нашей матрице по диагонали будут дисперсии признаков (т.к. i = j), а в остальных ячейках – ковариации соответствующих пар признаков. А в силу симметричности ковариации матрица тоже будет симметрична. Замечание:
Ковариационная матрица является обобщением дисперсии на случай многомерных случайных величин – она так же описывает форму (разброс) случайной величины, как и дисперсия. И действительно, дисперсия одномерной случайной величины – это ковариационная матрица размера 1x1, в которой ее единственный член задан формулой Cov(X,X) = Var(X). Итак, сформируем ковариационную матрицу Σ
для нашей выборки. Для этого посчитаем дисперсии X i и X j , а также их ковариацию. Можно воспользоваться вышенаписанной формулой, но раз уж мы вооружились Python’ом, то грех не воспользоваться функцией numpy.cov(X)
. Она принимает на вход список всех признаков случайной величины и возвращает ее ковариационную матрицу и где X – n-мерный случайный вектор (n-количество строк). Функция отлично подходит и для расчета несмещенной дисперсии, и для ковариации двух величин, и для составления ковариационной матрицы. Covmat = np.cov(Xcentered)
print covmat, "n"
print "Variance of X: ", np.cov(Xcentered)
print "Variance of Y: ", np.cov(Xcentered)
print "Covariance X and Y: ", np.cov(Xcentered)
OUT:
[[ 9.16666667 17.93002811]
[ 17.93002811 37.26438587]]
Variance of X: 9.16666666667
Variance of Y: 37.2643858743
Covariance X and Y: 17.9300281124
О"кей, мы получили матрицу, описывающую форму нашей случайной величины, из которой мы можем получить ее размеры по x и y (т.е. X 1 и X 2), а также примерную форму на плоскости. Теперь надо надо найти такой вектор (в нашем случае только один), при котором максимизировался бы размер (дисперсия) проекции нашей выборки на него. Замечание:
Обобщение дисперсии на высшие размерности - ковариационная матрица, и эти два понятия эквивалентны. При проекции на вектор максимизируется дисперсия проекции, при проекции на пространства больших порядков – вся ее ковариационная матрица.
Итак, возьмем единичный вектор на который будем проецировать наш случайный вектор X. Тогда проекция на него будет равна v T X. Дисперсия проекции на вектор будет соответственно равна Var(v T X). В общем виде в векторной форме (для центрированных величин) дисперсия выражается так: Соответственно, дисперсия проекции: Легко заметить, что дисперсия максимизируется при максимальном значении v T Σv. Здесь нам поможет отношение Рэлея. Не вдаваясь слишком глубоко в математику, просто скажу, что у отношения Рэлея есть специальный случай для ковариационных матриц: Последняя формула должна быть знакома по теме разложения матрицы на собственные вектора и значения. x является собственным вектором, а λ – собственным значением. Количество собственных векторов и значений равны размеру матрицы (и значения могут повторяться). Кстати, в английском языке собственные значения и векторы именуются eigenvalues
и eigenvectors
соответственно. Таким образом, направление максимальной дисперсии у проекции всегда совпадает с айгенвектором имеющим максимальное собственное значение, равное величине этой дисперсии
. И это справедливо также для проекций на большее количество измерений – дисперсия (ковариационная матрица) проекции на m-мерное пространство будет максимальна в направлении m айгенвекторов, имеющих максимальные собственные значения. Размерность нашей выборки равна двум и количество айгенвекторов у нее, соответственно, 2. Найдем их. В библиотеке numpy реализована функция numpy.linalg.eig(X)
, где X – квадратная матрица. Она возвращает 2 массива – массив айгензначений и массив айгенвекторов (векторы-столбцы). И векторы нормированы - их длина равна 1. Как раз то, что надо. Эти 2 вектора задают новый базис для выборки, такой что его оси совпадают с полуосями аппроксимирующего эллипса нашей выборки. Наибольший вектор имеет направление, схожее с линией регрессии и спроецировав на него нашу выборку мы потеряем информацию, сравнимую с суммой остаточных членов регрессии (только расстояние теперь евклидово, а не дельта по Y). В нашем случае зависимость между признаками очень сильная, так что потеря информации будет минимальна. «Цена» проекции - дисперсия по меньшему айгенвектору - как видно из предыдущего графика, очень невелика. Замечание:
диагональные элементы ковариационной матрицы показывают дисперсии по изначальному базису, а ее собственные значения – по новому (по главным компонентам). Часто требуется оценить объем потерянной (и сохраненной) информации. Удобнее всего представить в процентах. Мы берем дисперсии по каждой из осей и делим на общую сумму дисперсий по осям (т.е. сумму всех собственных чисел ковариационной матрицы). Замечание:
На практике, в большинстве случаев, если суммарная потеря информации составляет не более 10-20%, то можно спокойно снижать размерность. Для проведения проекции, как уже упоминалось ранее на шаге 3, надо провести операцию v T X (вектор должен быть длины 1). Или, если у нас не один вектор, а гиперплоскость, то вместо вектора v T берем матрицу базисных векторов V T . Полученный вектор (или матрица) будет являться массивом проекций наших наблюдений. V = (-vecs, -vecs)
Xnew = dot(v,Xcentered)
print Xnew
OUT:
[ -9.56404107 -9.02021624 -5.52974822 -2.96481262 0.68933859
0.74406645 2.33433492 7.39307974 5.3212742 10.59672425]
dot(X,Y)
- почленное произведение (так мы перемножаем векторы и матрицы в Python)
Нетрудно заметить, что значения проекций соответствуют картине на предыдущем графике. С проекцией удобно работать, строить на ее основе гипотезы и разрабатывать модели. Но не всегда полученные главные компоненты будут иметь явный, понятный постороннему человеку, смысл. Иногда полезно раскодировать, к примеру, обнаруженные выбросы, чтобы посмотреть, что за наблюдения за ними стоят. Это очень просто. У нас есть вся необходимая информация, а именно координаты базисных векторов в исходном базисе (векторы, на которые мы проецировали) и вектор средних (для отмены центровки). Возьмем, к примеру, наибольшее значение: 10.596… и раскодируем его. Для этого умножим его справа на транспонированный вектор и прибавим вектор средних, или в общем виде для всей выбоки: X T v T +m Xrestored = dot(Xnew,v) + m
print "Restored: ", Xrestored
print "Original: ", X[:,9]
OUT:
Restored: [ 10.13864361 19.84190935]
Original: [ 10. 19.9094105]
Разница небольшая, но она есть. Ведь потерянная информация не восстанавливается. Тем не менее, если простота важнее точности, восстановленное значение отлично аппроксимирует исходное. Итак, мы разобрали алгоритм, показали как он работает на игрушечном примере, теперь осталось только сравнить его с PCA, реализованным в sklearn – ведь пользоваться будем именно им. From sklearn.decomposition import PCA
pca = PCA(n_components = 1)
XPCAreduced = pca.fit_transform(transpose(X))
Параметр n_components
указывает на количество измерений, на которые будет производиться проекция, то есть до скольки измерений мы хотим снизить наш датасет. Другими словами – это n айгенвекторов с самыми большими собственными числами. Проверим результат снижения размерности: Print "Our reduced X: n", Xnew
print "Sklearn reduced X: n", XPCAreduced
OUT:
Our reduced X:
[ -9.56404106 -9.02021625 -5.52974822 -2.96481262 0.68933859
0.74406645 2.33433492 7.39307974 5.3212742 10.59672425]
Sklearn reduced X:
[[ -9.56404106]
[ -9.02021625]
[ -5.52974822]
[ -2.96481262]
[ 0.68933859]
[ 0.74406645]
[ 2.33433492]
[ 7.39307974]
[ 5.3212742 ]
[ 10.59672425]]
Мы возвращали результат как матрицу вектор-столбцов наблюдений (это более канонический вид с точки зрения линейной алгебры), PCA в sklearn же возвращает вертикальный массив. В принципе, это не критично, просто стоит отметить, что в линейной алгебре канонично записывать матрицы через вектор-столбцы, а в анализе данных (и прочих связанных с БД областях) наблюдения (транзакции, записи) обычно записываются строками. Проверим и прочие параметры модели – функция имеет ряд атрибутов, позволяющих получить доступ к промежуточным переменным: Вектор средних: mean_
Замечание:
explained_variance_ показывает выборочную
дисперсию, тогда как функция cov() для построения ковариационной матрицы рассчитывает несмещенные
дисперсии! Сравним полученные нами значения со значениями библиотечной функции. Print "Mean vector: ", pca.mean_, m
print "Projection: ", pca.components_, v
print "Explained variance ratio: ", pca.explained_variance_ratio_, l/sum(l)
OUT:
Mean vector: [ 5.5 10.31439392] (5.5, 10.314393916)
Projection: [[ 0.43774316 0.89910006]] (0.43774316434772387, 0.89910006232167594)
Explained variance: [ 41.39455058] 45.9939450918
Explained variance ratio: [ 0.99058588] 0.990585881238
Единственное различие – в дисперсиях, но как уже упоминалось, мы использовали функцию cov(), которая использует несмещенную дисперсию, тогда как атрибут explained_variance_ возвращает выборочную. Они отличаются только тем, что первая для получения мат.ожидания делит на (n-1), а вторая – на n. Легко проверить, что 45.99 ∙ (10 - 1) / 10 = 41.39. Все остальные значения совпадают, что означает, что наши алгоритмы эквивалентны. И напоследок замечу, что атрибуты библиотечного алгоритма имеют меньшую точность, поскольку он наверняка оптимизирован под быстродействие, либо просто для удобства округляет значения (либо у меня какие-то глюки). Замечание:
библиотечный метод автоматически проецирует на оси, максимизирующие дисперсию. Это не всегда рационально. К примеру, на данном рисунке неаккуратное снижение размерности приведет к тому, что классификация станет невозможна. Тем не менее, проекция на меньший вектор успешно снизит размерность и сохранит классификатор. Итак, мы рассмотрели принципы работы алгоритма PCA и его реализации в sklearn. Я надеюсь, эта статья была достаточно понятна тем, кто только начинает знакомство с анализом данных, а также хоть немного информативна для тех, кто хорошо знает данный алгоритм. Интуитивное представление крайне полезно для понимания того как работает метод, а понимание очень важно для правильной настройки выбранной модели. Спасибо за внимание! P.S.:
Просьба не ругать автора за возможные неточности. Автор сам в процессе знакомства с дата-анализом и хочет помочь таким же как он в процессе освоения этой удивительной области знаний! Но конструктивная критика и разнообразный опыт всячески приветствуются!
Компонента
Начальные собственные значения
Суммы квадратов нагрузок вращения
Итого
% Дисперсии
Кумулятивный %
Итого
% Дисперсии
Кумулятивный %
dimension0
5,442
90,700
90,700
3,315
55,246
55,246
,457
7,616
98,316
2,304
38,396
93,641
,082
1,372
99,688
,360
6,005
99,646
,009
,153
99,841
,011
,176
99,823
,007
,115
99,956
,006
,107
99,930
,003
,044
100,000
,004
,070
100,000
Метод выделения: Анализ главных компонент.
Матрица компонент a
Компонента
X1
,956
-,273
,084
,037
-,049
,015
X2
,986
-,138
,035
-,080
,006
,013
X3
,963
-,260
,034
,031
,060
-,010
X4
,977
,203
,052
-,009
-,023
-,040
X5
,966
,016
-,258
,008
-,008
,002
X6
,861
,504
,060
,018
,016
,023
Метод выделения: Анализ методом главных компонент.
a. Извлеченных компонент: 6
Матрица повернутых компонент a
Компонента
X1
,911
,384
,137
-,021
,055
,015
X2
,841
,498
,190
,097
,000
,007
X3
,900
,390
,183
-,016
-,058
-,002
X4
,622
,761
,174
,022
,009
,060
X5
,678
,564
,472
,007
,001
,005
X6
,348
,927
,139
,001
-,004
-,016
Метод выделения: Анализ методом главных компонент.
Метод вращения: Варимакс с нормализацией Кайзера.
a. Вращение сошлось за 4 итераций.

Модель
Нестандартизованные коэффициенты
Стандартизованные коэффициенты
t
Знч.
B
Стд. Ошибка
Бета
(Константа)
47414,184
1354,505
35,005
,001
Z1
26940,937
1366,763
,916
19,711
,001
Z2
6267,159
1366,763
,213
4,585
,001
Модель
R
R-квадрат
Скорректированный R-квадрат
Стд. ошибка оценки
dimension0
,941 a
,885
,881
10136,18468
a. Предикторы: (конст) Z1, Z2
b. Зависимая переменная: Y
Этап
Кластер объединен с
Коэффициенты
Следующий этап
Кластер 1
Кластер 2
Кластер 1
Кластер 2
,003
,004
,004
,005
,005
,005
,005
,006
,007
,007
,009
,010
,010
,010
,010
,011
,012
,012
,012
,012
,012
,013
,014
,014
,014
,014
,015
,015
,016
,017
,018
,018
,019
,019
,020
,021
,021
,022
,024
,025
,027
,030
,033
,034
,042
,052
,074
,101
,103
,126
,163
,198
,208
,583
1,072

Этап
Кластер объединен с
Коэффициенты
Этап первого появления кластера
Следующий этап
Кластер 1
Кластер 2
Кластер 1
Кластер 2
,003
,004
,004
,005
,005
,005
,005
,007
,009
,010
,010
,011
,011
,012
,012
,014
,014
,014
,017
,017
,018
,018
,019
,021
,022
,026
,026
,027
,034
,035
,035
,037
,037
,042
,044
,046
,063
,077
,082
,101
,105
,117
,126
,134
,142
,187
,265
,269
,275
,439
,504
,794
,902
1,673
2,449






Вычисление главных компонент

![]()
![]()

![]()
![]()


![]()
![]()
![]()
![]()

![]()



Математика вообще очень красивая и изящная наука, но порой ее красота скрывается за кучей слоев абстракции. Показать эту красоту лучше всего на простых примерах, которые, так сказать, можно покрутить, поиграть и пощупать, потому что в конце концов все оказывается гораздо проще, чем кажется на первый взгляд – самое главное понять и представить.Шаг 1. Подготовка данных

Оператор, обратный сдвигу будет равен вектору изначальных средних значений – он понадобится для восстановления выборки в исходной размерности.
Шаг 2. Ковариационная матрица

(Напомню, что в Python матрица представляется массивом-столбцом массивов-строк.)
Шаг 3. Собственные вектора и значения (айгенпары)
Мне кажется, это звучит намного более красиво (и кратко), чем наши термины.
На этом графике мы апроксимировали нашу выборку эллипсом с радиусами в 2 сигмы (т.е. он должен содержать в себе 95% всех наблюдений – что в принципе мы здесь и наблюдаем). Я инвертировал больший вектор (функция eig(X) направляла его в обратную сторону) – нам важно направление, а не ориентация вектора.Шаг 4. Снижение размерности (проекция)
Таким образом, наш больший вектор описывает 45.994 / 46.431 * 100% = 99.06%, а меньший, соответственно, примерно 0.94%. Отбросив меньший вектор и спроецировав данные на больший, мы потеряем меньше 1% информации! Отличный результат!Шаг 5. Восстановление данных
Вместо заключения – проверка алгоритма
- Вектор(матрица) проекции: components_
- Дисперсии осей проекции (выборочная): explained_variance_
- Доля информации (доля от общей дисперсии): explained_variance_ratio_

| Статьи по теме: | |
|
Заговор и обряд на кольцо Заговор на кольцо на привлечение любви
Если хотите обогатиться, стать любимчиком Фортуны, исполнить желание,... Модный и стильный аксессуар в женском гардеробе: шарф-капюшон спицами Описание вязания шарфа-капюшона
Уникальный шарф-капюшон служит головным убором и шарфом одновременно! Он... День авиации (День Воздушного Флота)
День Военно-воздушных сил отмечается в России 12 августа в соответствии... | |




